AIで切り開くスーパーマーケットの未来ー販売予測の新たな可能性ー

小売業の永遠の課題である販売予測に対して、BigQueryを用いて精度向上を目標とした検証をおこないました。
本記事では、検証の過程や利用したモデルについて触れながら検証の結果をまとめています。
解決したい課題
販売予測は小売業界における永遠の課題であり、業績予測だけでなく、その後の商品の発注に関連する物流コストの削減や在庫負担の軽減など、多岐に渡る影響を及ぼします。
特に、毎日多くの顧客が訪れるスーパーマーケット業界では、その重要性が際立っています。
しかし、これまでの販売予測は、直近の業績を反映するだけだったり、経営者自身の主観的な判断に依存したりと、客観的なデータ(例:販売週期のトレンドなど)を用いた合理的な推定が困難でした。
そこで今回、AIや機械学習の力を活用し、過去のデータから統計的特性を抽出することで、合理的な販売トレンドを予測し、個人的な主観が予測精度に悪影響を及ぼすことを防ぎたいと考えています。
また、顧客と協力して単なる概念的なモデルに留まらず、各店舗、さらには各商品の階層にまで掘り下げて理論的なモデルを販売実務と明確に結びつけることを目指します。そのため、各店舗の特性や商品の性質に応じた複数のモデルを構築し、それを効率的に一度に実現する必要があります。
今回の取り組み
上述の要件を満たすため、今回はGoogle Cloud Platformを作業プラットフォームとして採用しました。特に、Big QueryデータベースとそのSQL構文を利用し、さまざまなシナリオで迅速にデータ整理やモデル構築を行うことを目指しています。Big Queryデータベースには科学的なモデルが多数組み込まれており、そのML構文を活用することで複数のモデル構築とパラメータ最適化を同時に行い、最良のパフォーマンスを発揮することができます。
利用したデータ
今回使用するデータは、あるスーパーマーケットの2年間にわたる50店舗の日次商品取引データです。このデータは販売日時、数量、金額を含む商品データとして扱うことができるほか、別の視点からは商品ごとの時系列データとみなすこともできます。
注目すべき点として、50店舗と10万点以上の商品にわたる日次販売データが含まれているため、総データ件数は数千万件を超えます。これはモデル構築において大きな負荷となるため、実装前にデータを前処理して計算リソースの負荷を軽減する必要があります。
また、金額、数量、日時といった数値データだけでなく、商品名やカテゴリといった名義データも含まれており、この複雑なデータ構成を最大限活用するため、最初にboosted treeモデルを選択しました。
モデルの選択と課題
選択したboosted treeモデルには複数の種類がありますが、代表的なものとしてXGBoostが挙げられます。このモデルは異なるデータ型を活用できるだけでなく、アルゴリズムが各決定木の重みを自動調整し、過学習を抑制して最適解を導き出す特徴を持っています。

(出典: 米国データサイエンティストのブログ)
一方で、XGBoostには計算リソースの大量消費やパラメータ調整の難しさといった欠点もあります。試験的に、ある店舗の特定商品に絞り、販売データを使用してモデル構築を行いました。対象データは2年間のもので、初期設定はそれほど複雑ではありませんでした。しかし、モデル構築には約1時間を要し、大量の計算リソースが消費されました(今回のデータでは約1GBのメモリが必要)。
さらに、販売データには不定期に行われたセールスイベントの影響で、予測が困難な非常に高い外れ値が含まれています。これによりモデルの精度が期待した水準を下回る結果になりました。
時系列モデルへの移行
商業利用モデルとして、低精度の結果は受け入れられないため、単一の店舗や商品ごとにXGBoostを利用してモデル構築を行う方法は、時間や計算リソースのコストが非常に高くなるという課題が浮き彫りとなりました。
現状の制約を考慮し、Boosted Treeモデルの使用を断念。データ構造を理解した上で、時系列分析の視点から新たなモデルを構築することを選びました。
次に利用したBigQuery内のARIMA_PLUSモデルは、統計的なARIMAモデルに基づいています。このモデルは自己回帰(AR)、移動平均(MA)、差分(I)の3要素を組み合わせたもので、データに基づいてトレンドやパターンを予測するものです。AR(p)モデルは現在のデータが過去のデータに影響される範囲を示し、MA(q)モデルは現在のデータが過去の独立した誤差に基づいていることを示します。これら2つの視点を統合するために差分I(d)が導入され、ARIMA(p, d, q)モデルが形成されます。
BigQueryでは、AUTO_ARIMA=Trueを設定することで、最適なパラメータを自動で計算し、ARIMA_PLUSモデルを効率よく利用できます。ただし、ARIMAは単変数モデルであるため、他の変数を含めた予測を行う場合、追加のデータ処理や新しいモデルの構築が必要となります。
自己相関関数(ACF)および偏自己相関関数(PACF)を用いて今回のデータを分析したところ、幸い、現在のデータが過去2週間から3週間程度のデータに影響されていることが確認されました。このため、ARIMAモデルのパラメータは0から3の範囲で合理的に評価することができます。
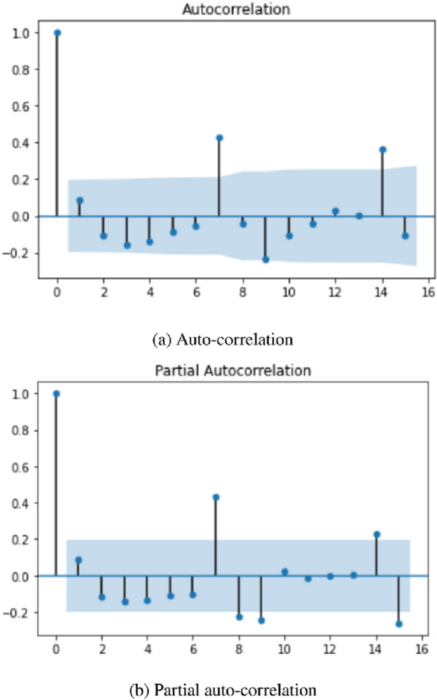
(出典: ResearchGate.net)
さらに、計算負荷を軽減するため、すべての商品データを使用するのではなく、カテゴリ単位でデータを統合しました。また、日次データを週次データに変換し、データ量を削減しました。同時に、外れ値の影響を軽減するためにデータスムージングを行い、予測精度の向上を図りました。具体的には、週ごとの平均値と標準偏差を計算し、平均値から1.5倍以上の標準偏差を超えるデータポイントを外れ値として扱いました。これらの外れ値は、前後の週の平均値で補完され、データの連続性を保ちつつ、セールスイベントによる影響を排除しました。
現在の結果
今回のモデル構築において、予測結果と実際のデータのトレンドを比較したところ、約70%のデータポイントが誤差30%以内で一致していることが確認されました。この結果から、2年間にわたる販売データをカテゴリごとに統合し、外れ値を除去した後、トレンド予測に活用できることが明らかになりました。
特に、BigQueryを利用することで複数のARIMA_PLUSモデルを同時に構築し、自動でパラメータを最適化することが可能となっています。このプロセスによって、従来の個別構築に比べて大幅な効率化が実現しました。さらに、各モデルのパラメータ設定がBigQuery内に保存されるため、個別モデルを抽出して詳細な検証を行うことも可能です。また、これらのモデルを使用することで、次のタイムポイントの予測だけでなく、将来的な一定期間にわたるタイムシリーズの予測を行うこともできます。
ただし、前述のようにARIMA_PLUSは単変数モデルであるため、他の変数を含めた予測を行う場合や予測精度をさらに向上させたい場合、追加のデータ処理や補助的なモデル(Affiliate Model)の構築が必要となります。また、直接的にモデル自体を変更することも検討事項の一つです。
現在の結果は一定の精度を確保していますが、さらに高度なモデルを追求する場合には、例えば多変量モデルや深層学習を用いたアプローチが考えられます。このようなモデルを導入することで、複数の要因を考慮した包括的な予測が可能になると期待されます。
もし読者の皆さまが機械学習モデルの構築に興味をお持ちでしたり、私たちと共に機械学習やAIを活用して世界を変える取り組みに参加したいと思われましたら、ぜひお気軽にお問い合わせください。
お問い合わせフォームはこちら





